
作者:Skytier
循环神经网络(RNN)可是在语音识别、自然语言处理等其他领域中引起了变革!
应用场景
循环神经网络(RNN)其实就是序列模型,我们先来看看其应用场景。

在语音识别时,给定了一个输入音频片段 X ,并要求输出对应的文字记录 Y 。这里的输入和输出数据都是序列模型,输入 X 是一个按时播放的音频片段,输出 Y 是一系列文字。
音乐生成问题也是一样,输出数据 Y 是序列,而输入数据 X 可以是空集,也可以是个单一的整数(代表音符)。
而系列模型在 DNA 序列分析中也十分有用,DNA 可以用 A、C、G、T 四个字母来表示。所以给定一段 DNA 序列,你能够标记出哪部分是匹配某种蛋白质的吗?
以上所有类似问题都可以被称作使用标签数据(X,Y)作为训练集的监督学习,输入数据 X 或者输出数据 Y 是序列,即使两者都是序列也有数据长度不同的问题。
模型构建
比如建立一个序列模型,它的输入语句是这样的:“Sam Li and Tom date on Tuesday.”。然后模型是可以自动识别句中人名位置的命名实体识别模型,可以用来查找不同类型的文本中的人名、公司名、时间、地点、国家名和货币名等等。
假定输入数据 x,序列模型的输出 y,使得输入的每个单词都对应一个输出值,同时 y 还需要表明输入的单词是否是人名的一部分。
首先输入语句是 7 个单词组成的时序序列,所以最终会有 7 个特征集 x:x<1>,x<2>,...,x<7>,同时可以索引其序列中的位置。Tx 表示输出序列的长度,这里 Tx=7。
同理,输出数据也是一样,分别对应 y<1>,y<2>,...,y<7>,Ty 表示输出序列的长度。
因此总结来说,训练样本 i 的序列中第 t 个元素用 x(i)表示,
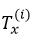
代表第 i 个训练样本的输入序列长度,y(i)表示第 i 个训练样本中第 t 个元素,
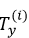
就是第 i 个训练样本的输出序列的长度。
那么问题来了,首先我们需要准备一个比较大的词典库,可能该库里的第一个单词是 a,and 出现在第 367 个位置上,Sam 是在 7459 这个位置,Tom 则在 8674。
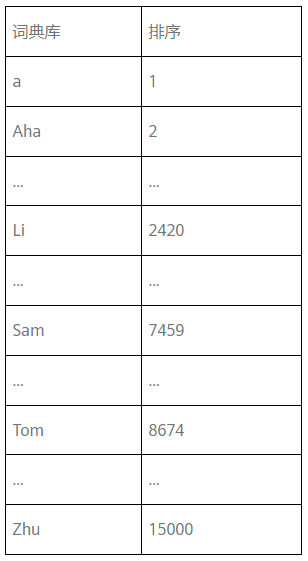
那么我们就可以在这个词典库的基础上遍历训练集。
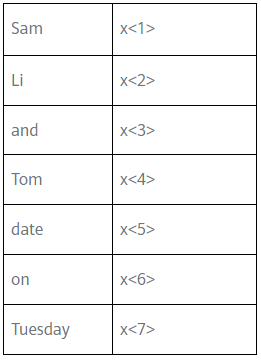
那么也就是说,Sam 由 x<1>表示,其是一个第 7459 行是 1,其余值都是 0 的向量;Li 由 x<2>表示,其是一个第 2420 行是 1,其余值都是 0 的向量。
通常我们称这种 x 指代句子里的任意词为 one-hot 向量,只有一个值是 1,其余值都是 0,所以整句话中我们会有 7 个 one-hot 向量,用序列模型在 X 和 Y 目标输出之间学习建立一个映射关系。
PS:如果遇到了一个在你词表中的单词,可以创建一个 Unknow Word 的伪造单词,用<UNK>作为标记。
模型解释
通常情况下,我们会首先选取标准的神经网络,输入 7 个 one-hot 向量,经过一些隐藏层,最终会输出 7 个值为 0 或 1 的项,表明每个输入单词是否是人名的一部分。
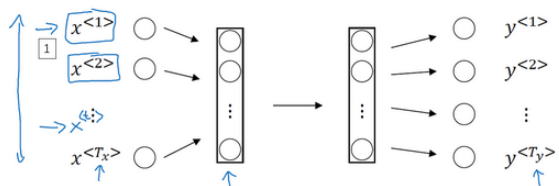
但最后我们总会遇到这样的问题:
1.输入和输出数据的长度并不完全一致,即使采用填充(pad)或零填充(zero pad)使每个输入语句都达到最大长度,但最后的表达式会很奇怪。
2.简单的神经网络并不会共享从文本的不同位置上学到的特征。因为我们希望,如果首次学习的时候我们已经知道了 Tom 是人名,那么当 Tom 出现在其他位置时,其并不能够自动识别,因此也不能够减少模型中参数的数量。
那么循环神经网络为啥会比普通的神经网络更加出众呢?
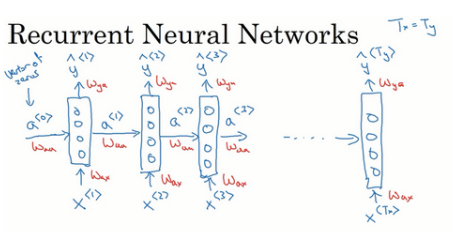
以从左到右的顺序读这个句子,第一个单词就是 x<1>,将其输入一个神经网络层,同时尝试预测输出,判断这是否为人名;下面精彩的部分来啦,循环神经网络中当它读到句中的第二个单词时,假设是 x<2>,它不是仅用 x<2>就预测出
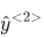
还会输入一些来自时间步 1 的信息,那么时间步 1 的激活值就会传递到时间步 2。在下一个时间步,循环神经网络输入了 x<3>,尝试预测输出了
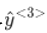
,...,一直到最后一个时间步,输入 x,然后输出
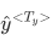
在每一个时间步中,循环神经网络会传递一个激活值到下一个时间步中用于计算,同时还需要使用零向量作为零时刻的伪激活值输入神经网络
另外循环神经网络是从左向右扫描数据,同时每个时间步的参数也是共享的,用 Wax 来表示从 x<1>到隐藏层的连接的一系列参数,每个时间步使用的都是相同的 Wax 参数,而激活值是由参数 Waa 决定的,输出结果由 Way 决定。
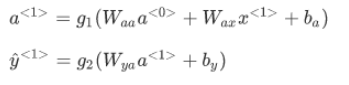
先输入零向量 a<0>,接着进行前向传播过程,计算激活值 a<1>,然后再计算 y<1>。
更普遍来说,在 t 时刻:
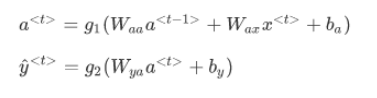
为了更加简化一点,定义 Wa:
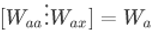
假设 a 是 100 维的,x 是 10,000 维的,那么 Waa 是(100,100)维的矩阵,Wax 是(100,10000)维,Wa 为(100,10100)。
同样,假定
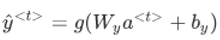
Wy 表明它是计算 y 类型的量的权重矩阵,而 Wa 和 ba 则表示这些参数是用来计算激活值的。
